理想的翻译视频应具备以下特性:字幕准确、长度适宜,配音音色与原声一致,且字幕、声音、画面完美同步, 出于易用性考虑,软件默认配置并非最佳,你可以参考以下说明,自行调整每个步骤的最佳配置。
第一步:语音识别
将视频中的语音转换为对应语言的字幕文件
如果原始音视频有背景音或噪声,建议点击主界面
设置更多参数并选中保留人声背景声,若不想翻译后重新将背景音嵌入视频中,可取消重新嵌入背景声,如此处理后,排除噪声背景声干扰,识别效果会更准确
非中文最佳配置:
- 免费
faster-whisper(本地) large-v3模型|open-whisper(本地) large-v3模型 - 收费 OpenAI语音识别API
- 免费
中文最佳配置:
- 免费 Qwen-ASR(本地) 阿里FunASR
- 收费:
豆包语音识别大模型极速版|阿里百炼ASR
日语最佳
- 免费:
open-whisper(本地) large-v3模型 , Huggingface_ASR ->reazon-research/japanese-wav2vec2-large-rs35kh - 收费: OpenAI语音识别API
- 免费:
小语种最佳配置:
- 免费
open-whisper(本地) large-v3模型 - 收费:
Gemini大模型识别|OpenAI语音识别API
- 免费
注意: 如果没有N卡或未配置CUDA环境未启用CUDA加速,使用本地模型时处理速度极慢。显存不够大时可能崩溃。
针对竖屏短视频,可在
高级选项--语音识别区域适当减小最长语音持续时间(秒)和最短语音持续时间(毫秒),有利于生成短小的字幕,防止超出屏幕,注意最短语音持续时间(毫秒)不建议低于1秒同时也可在主界面中选中
二次识别,并在高级选项--语音识别区域设置合适的二次最长语音持续时间(秒)和二次最短语音持续时间(毫秒)。同时建议在高级选项同个位置,将
中日韩字幕字符数调整为10-15个字符,其他语言字幕字符数条为20-40避免字幕过长超出屏幕如果字幕仍太长,可尝试点击
设置更多参数--修改硬字幕样式--字体大小,减小一到二号字体删除标点:
设置更多参数--默认标点改为删除标点, 字幕感官更好些如果未选择
clone音色,也可以尝试选中LLM重新断句
第二步:字幕翻译
目标: 将第一步生成的字幕文件翻译成目标语言。
对应控制元素: “翻译渠道”行
最佳配置:
- 首选AI渠道(收费): DeepSeek、OpenAI ChatGPT(最新上线的模型) 、Gemini(最新上线模型)
- 选中
发送完整字幕
第三步:配音
- 目标: 根据翻译后的字幕文件生成配音。
- 对应控制元素: “配音渠道”行
- 最佳配置:
- 免费:Edge-TTS: 免费并支持所有语种
- 免费:中英日韩:
Qwen-TTS(本地)、F5-TTS/Index-TTS/GPT-SOVITS/CosyVoice(本地) - 收费:豆包语音合成2.0 / Qwen-TTS(bailian) / 302.AI / Minimaxi / OpenAI-TTS
- 克隆语音:OmniVoice-TTS(本地)、 Qwen-TTS(本地)、GPT-SOVITS、CosyVoice、F5-TTS、Index-TTS、Chatterbox
第四步:字幕、配音、画面同步对齐
目标: 将字幕、配音和画面进行同步处理。
对应控制元素:
同步对齐行
最佳配置:
- 选中二次识别,将在配音完成后对配音文件再次语音识别生成时间轴精准的字幕
- 中文翻译成英文时,可设置
配音语速值 (例如10或15) 以加快配音速度,因为英文句子通常较长。 - 选中
配音加速, 若可接受处理较慢和视频质量下降,也可同时选择视频慢速,强制对齐字幕、声音和画面,也可以两者只选中一个。
第五步:其他有助于质量提升的选项
- 选中
发送完整字幕,同时选中菜单-工具-高级选项-AI翻译附带完整原字幕,并将AI翻译渠道每批次字幕行数设为100或更大,将得到更好的翻译质量,但注意,必须使用具有极大上下文的在线AI大模型,例如 GPT-5.5+/Gemini-3.1-pro+/DeepSeek-v4等
使用clone角色克隆原音色配音时
- 如果使用
clone配音角色时,请打开菜单--工具--高级设置--语音识别参数区域:建议将最短语音持续毫秒设为 3000 ,将最长语音持续秒数设为 10 ,因为 语音克隆时会自动将字幕时长对应的原始语音片段作为参考音频,而多数配音渠道均要求该参考音频时长在 3-10s 之间,否则配音很可能失败。 同时应该选中Whisper预分割音频以及合并过短字幕到相邻,以确保字幕时长能够落在 3-10s 之间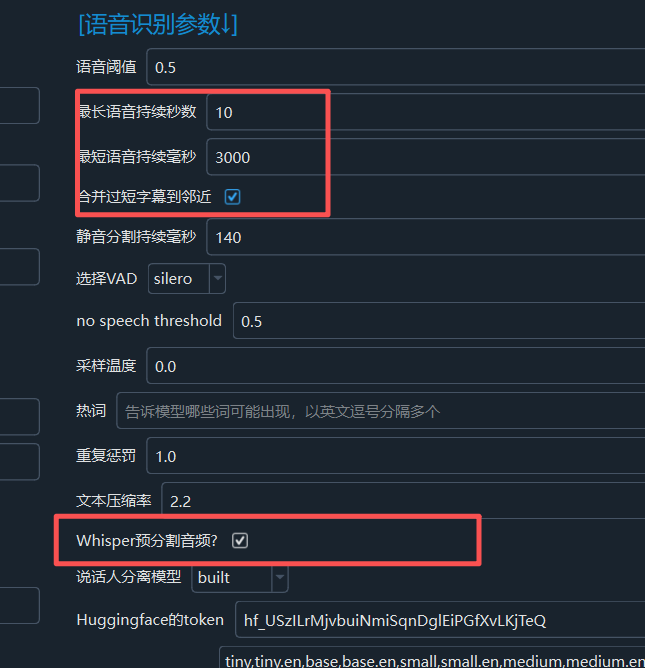
- 如果你的字幕很多都小于3s,建议使用
OmniVoice-TTS配音渠道,在短参考音频下能避免出错 - 翻译渠道 使用AI引擎,例如 DeepSeek 或 OpenAI ChatGPT 等, 并且选中
发送完整字幕 - 语音识别渠道 对于中文建议
豆包语音大模型极速版/Qwen-ASR/FunASR/阿里百炼等,英文Faster-whisper+large-v3模型,并且选中默认断句 - 如果需要重新嵌入原始视频的背景音,点击
设置更多参数-选中分离人声背景声,如果不需要,则选中降噪