语音识别中的VAD参数调整
在视频翻译的语音识别阶段,生成的字幕有时可能过长(几十秒甚至几分钟),有时又过短(不到1秒)。通过调整VAD(语音活动检测)参数,可以优化这些问题,使字幕更符合实际语音内容。
VAD 是什么
VAD 是一个语音活动检测工具,用于识别音频中的语音部分,并将其与静音或噪音分离。它可以与语音识别工具(如 Whisper)结合使用,在识别前后检测和分割语音片段,从而提升识别效果。
在 3.92版本后,默认vad模型为 ten-vad,你可以在菜单-工具-高级选项中,手动切换为silero
参数详解及调整建议
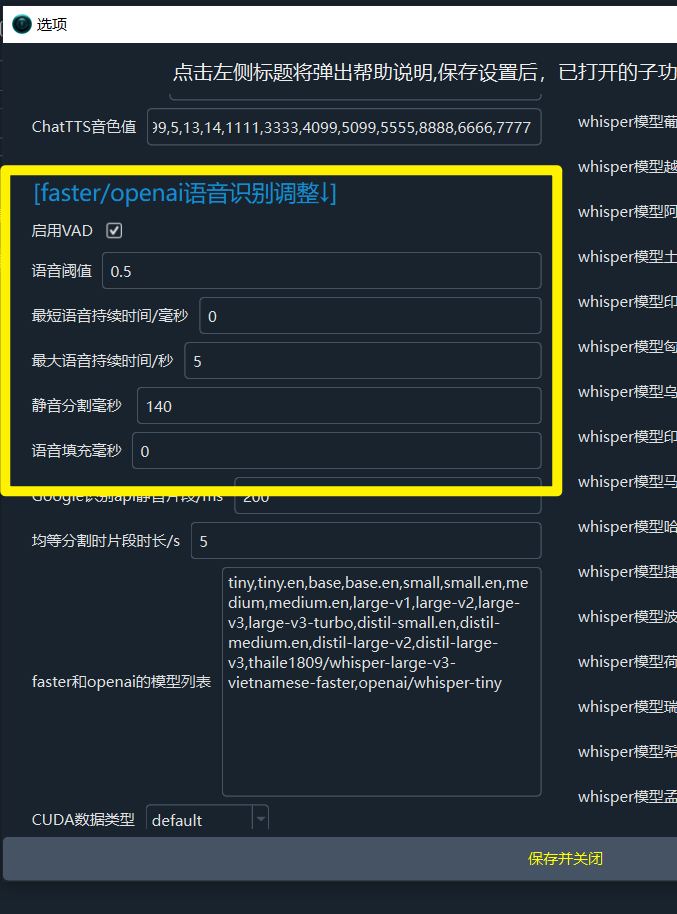
语音阈值: 表示音频片段被认为是语音的最低概率。VAD 会为每个音频片段计算语音概率,超过此阈值的部分被视为语音,反之视为静音或噪音。越小越灵敏但可能误将噪声视为语音最长语音持续秒数: 限制单个语音片段的最大长度。超过此时长时强制分割。填写数字,单位是秒最短语音持续毫秒: 最短语音持续的时长,如果某条字幕时长小于该值对应ms,则尝试将该字幕合并进相邻字幕中,单位是毫秒合并过短字幕到邻近: 只有选中该项,才会合并短字幕静音分割持续毫秒: 在语音结束时,需等待的静音时间达到此值后,才会分割出语音片段。填写数字,单位ms,也就是只在大于此值的静音片段处分割选择VAD: 选择要使用的VADno speech threshold: 减小可降低幻觉但可能遗漏文字采样温度: 采样温度热词: 告诉模型哪些词可能出现,以英文逗号分隔多个重复惩罚: 增大该值有利于减少重复文本压缩率: 减小该值有利于减少重复Whisper预分割音频?: 是否提前将音频切割为句子片段后再发给whisper模型识别?若使用clone配音角色,请选中,并将最短语音设为3000,最大语音设为10,提供语音克隆可靠性