对识别结果进行重新断句
为了提升字幕断句的自然度和准确性,pyVideoTrans 从 v3.69 版本开始,引入了基于 AI的LLM重新断句功能和基于标点符号的本地重新断句,旨在优化字幕处理体验。
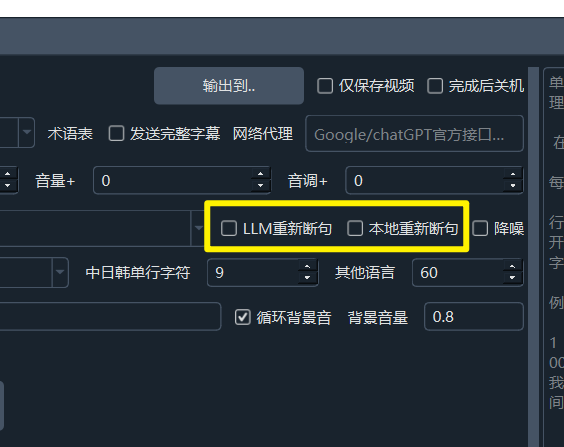
1. 使用 LLM 大模型对语音识别结果重新断句
工作原理:
当您使用 faster-whisper(本地)、openai-whisper(本地) 或 parakeet-tdt 进行语音识别,并启用了LLM重新断句功能后:
- pyVideoTrans 会将识别到的包含单词级时间戳的
字/单词发送给您配置的 LLM 进行重新断句。 - LLM 会根据
/videotrans/prompts/recharge/recharge-llm.txt文件中的提示词指导,对文本进行智能断句。
- 断句完成后,结果将被重新整理为标准的 SRT 字幕格式,供后续翻译或直接使用。
- 如果 LLM 重新断句失败,软件将自动回退,使用
faster-whisper/openai-whisper/parakeet-tdt自身提供的断句结果。
细化控制
要成功启用并使用此功能,请确保满足以下条件:
选择语音切割模式:需设置为
整体识别。
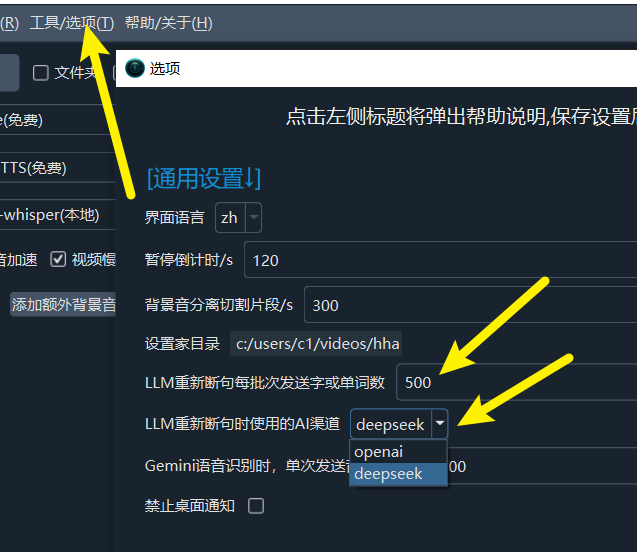
配置 LLM API:在 菜单 -> 翻译设置 -> OpenAI API 及兼容 AI或DeepSeek 中,正确填写您的 API Key (SK)、选择模型名称,并设置其他相关参数。
默认将使用
OpenAI API进行重新断句,可以在菜单--工具--高级选项--LLM重新断句使用的AI渠道中切换为DeepSeek在
工具--选项--高级选项--LLM重新断句每批次发送数量中调整数值,默认每 500 个字或单词发送一次断句请求,该值越大,断句效果越好,但如果输出超过了所用模型允许的最大输出token,会引发错误。同时若增大该值,也需要相应调大下条所述的最大输出token
2. 使用 本地重新断句
如果不想使用LLM重新断句,也可选择本地重新断句,将基于标点符号对识别出的字词重新断句,如果标点严重缺失,效果会比较差。
同样仅适用于faster-whisper/openai-whisper/parakeet-tdt 这3种语音识别渠道