Use LLM Large Language Models to Re-punctuate Speech Recognition Results
To improve the naturalness and accuracy of subtitle segmentation, pyVideoTrans has introduced intelligent re-punctuation based on LLM (Large Language Model) starting from version v3.69, aiming to optimize your subtitle processing experience.
Background: Limitations of Traditional Punctuation
In v3.68 and earlier versions, we provided a "Re-punctuate" function. After faster-whisper, openai-whisper, or deepgram completed the initial speech recognition, this function would call the Alibaba model to perform secondary segmentation and punctuation of the generated subtitles.
The original "Re-punctuate" function also had some shortcomings:
- Inconvenient for first-time use: It required downloading three large model files online from ModelScope.
- Poor efficiency and effectiveness: The processing speed was slow, and the punctuation effect was sometimes still not ideal.
Although models such as faster-whisper can output punctuation results themselves, in practical applications, problems such as sentences being too long, too short, or punctuated awkwardly often occur.
Innovation: v3.69+ Introduces LLM Intelligent Re-punctuation
To solve the above problems, starting from version v3.69, we have comprehensively upgraded the "Re-punctuate" function to LLM Re-punctuation.
How it works:
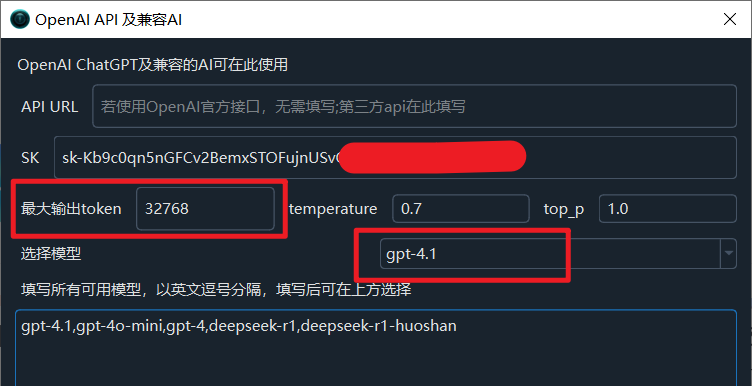
When you use faster-whisper (local), openai-whisper (local), or Deepgram.com for speech recognition, enable the new LLM Re-punctuation function, and have correctly configured the model, API Key (SK), and other information in Translation Settings - OpenAI API and Compatible AI:
- pyVideoTrans will send the recognized
characters/wordswith word-level timestamps in batches of 3000 to the LLM you configured for re-punctuation. - The LLM will be guided by the prompts in the
/videotrans/recharge-llm.txtfile to intelligently punctuate the text. - After punctuation is completed, the results will be reorganized into a standard SRT subtitle format for subsequent translation or direct use.
- If LLM re-punctuation fails, the software will automatically fall back and use the punctuation results provided by
faster-whisper/openai-whisper/deepgramitself.
Necessary Conditions for Enabling "LLM Re-punctuation"
To successfully enable and use this feature, please ensure that the following conditions are met:
Check to Enable: In the software interface, select the LLM Re-punctuation option.
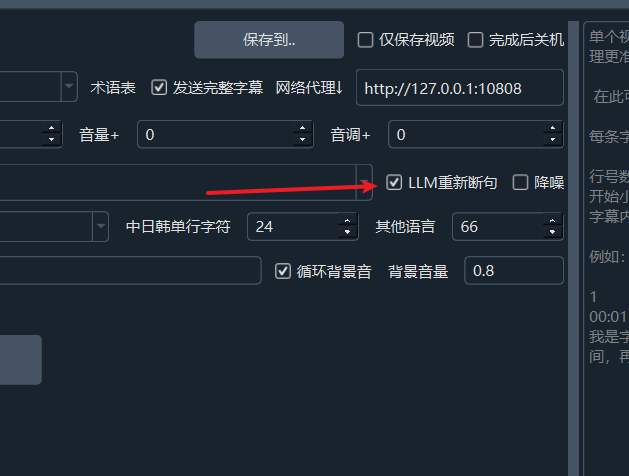
Specify Speech Recognition Model: The speech recognition engine must be one of the following three:
faster-whisper (local)openai-whisper (local)Deepgram.com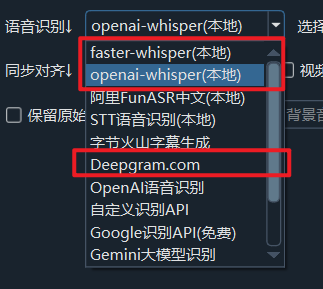
Select Speech Segmentation Mode: It needs to be set to
Overall Recognition.
Configure LLM API: In Menu -> Translation Settings -> OpenAI API and Compatible AI, correctly fill in your API Key (SK), select the model name, and set other related parameters.
Adjusting and Optimizing LLM Re-punctuation Effects
Adjust the value in
Tools -- Options -- Advanced Options -- LLM Re-punctuation Number of words sent per batch. By default, a punctuation request is sent every 3000 characters or words. The larger the value, the better the punctuation effect. However, if the output exceeds the maximum output token allowed by the model used, it will cause an error. At the same time, if you increase this value, you also need to increase the maximum output token mentioned in the next item accordingly.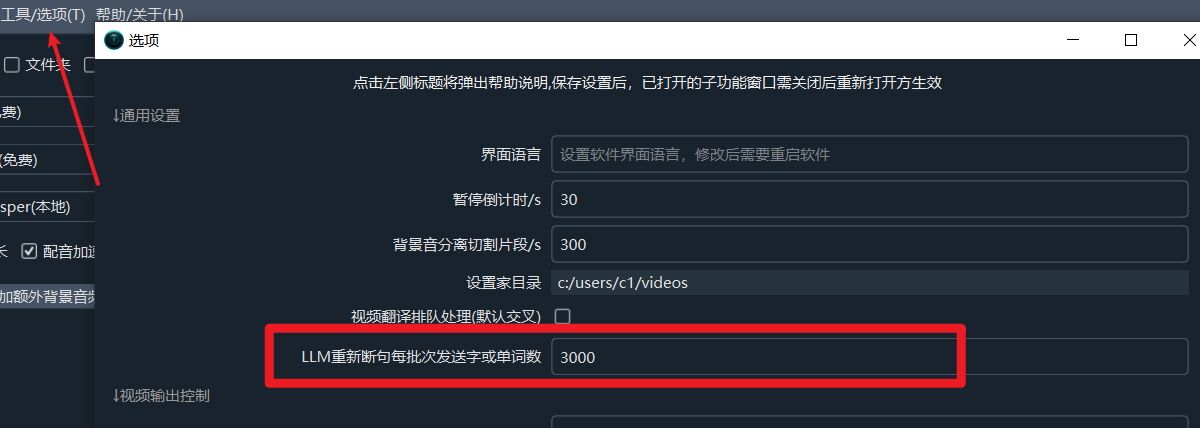
You can modify the Menu --> Translation Settings -> OpenAI API and Compatible AI -> Maximum Output Token according to the maximum output token allowed by the LLM model used, the default is
4096, the larger the value, the larger theLLM Re-punctuation Number of words sent per batchis allowed to be.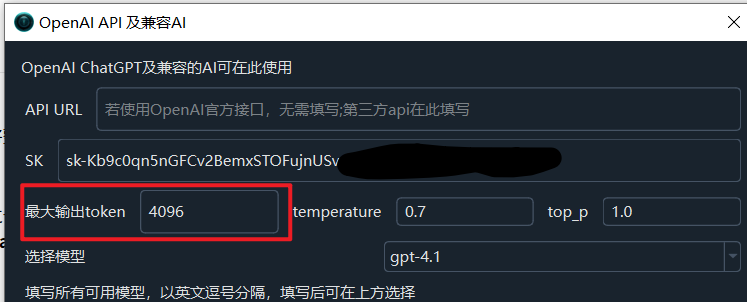
You can adjust and optimize the prompts in
videotrans/recharge-llm.txtin the software directory to achieve better results.
To summarize: the larger the Maximum Output Token, the more characters or words allowed for LLM Re-punctuation Number of words sent per batch, and the better the punctuation effect, but the Maximum Output Token must not exceed the value supported by the model itself, otherwise an error will inevitably occur. The output corresponding to each word or character after punctuation in LLM Re-punctuation Number of words sent per batch may consume multiple tokens, so please increase this value carefully and slowly to avoid the output exceeding the Maximum Token and causing an error.
How to Query the Maximum Output Token of Different Models?
Note that it must be the Maximum Output Token, not the
Context Token. Usually the context length is very large, such as 128k, 256k, 1M, etc., while the Maximum Output Token is much smaller than the context token, generally 8k(8092) / 32k(32768), etc.
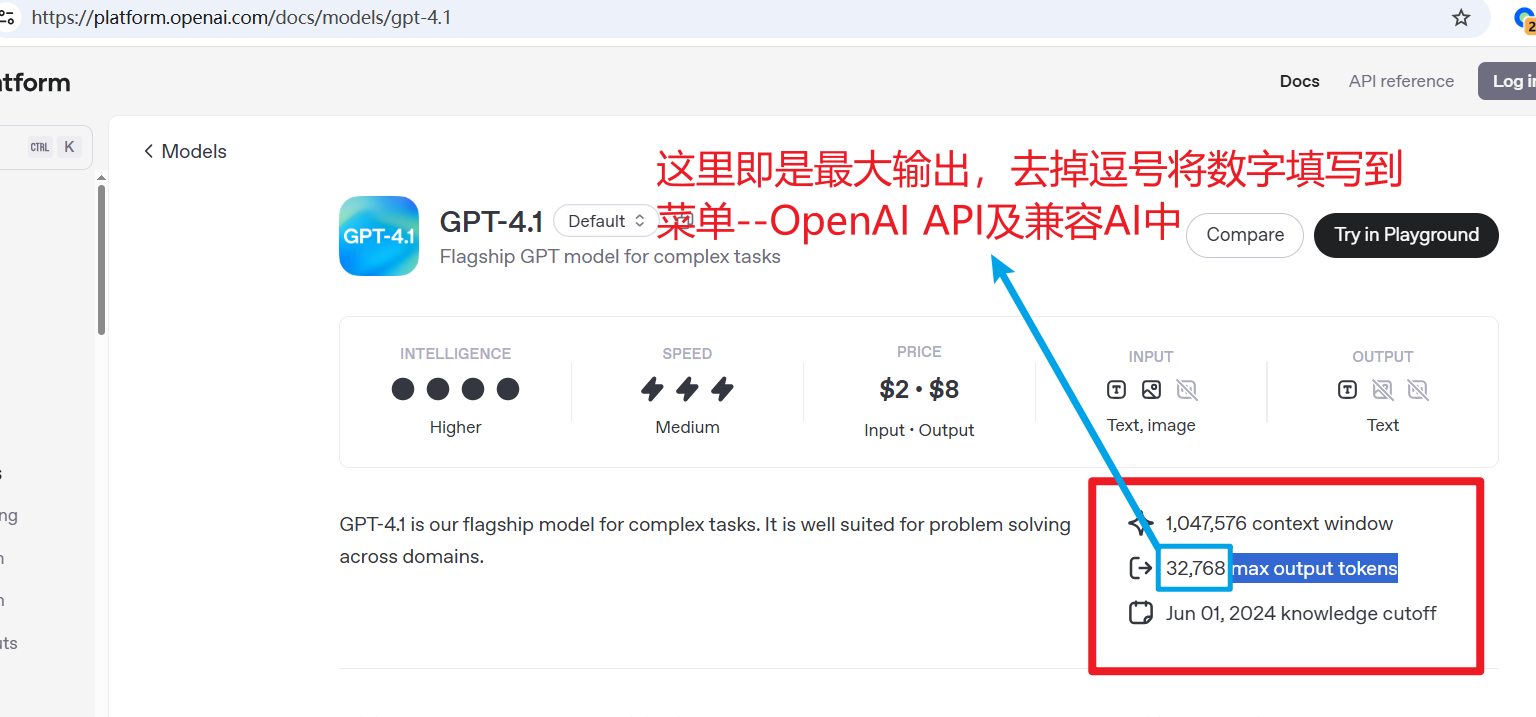
1. OpenAI Series Models
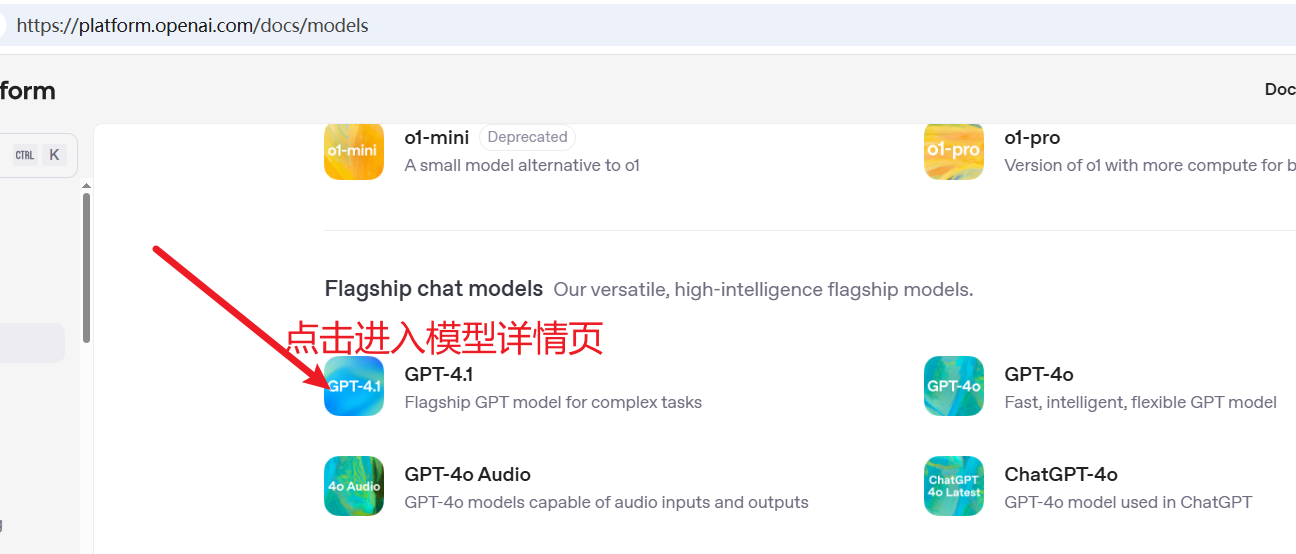
You can view the details of each model in the official OpenAI model documentation: https://platform.openai.com/docs/models
- Click the name of the model you plan to use to enter the details page.
- Look for related descriptions such as "Max output tokens".
2. Other OpenAI-Compatible Models
For other large language model providers compatible with the OpenAI API, their maximum output token (not context length) is usually listed in their official API documentation or model instructions.
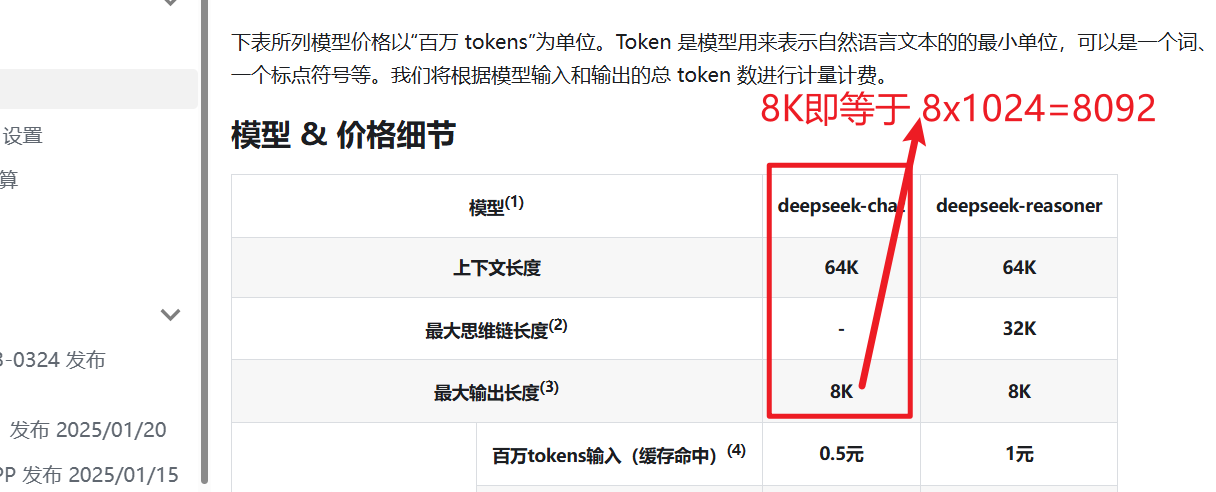
- DeepSeek (e.g.
deepseek-chatordeepseek-reasoner): Refer to its pricing or model description page, such as: https://platform.deepseek.com/api-docs/pricing
SiliconFlow: Find it in its model documentation: https://docs.siliconflow.cn/cn/faqs/misc#2-%E5%85%B3%E4%BA%8Emax-tokens%E8%AF%B4%E6%98%8E

Alibaba Bailian: Find the parameter limits of specific models in the model square or model documentation: https://help.aliyun.com/zh/model-studio/models
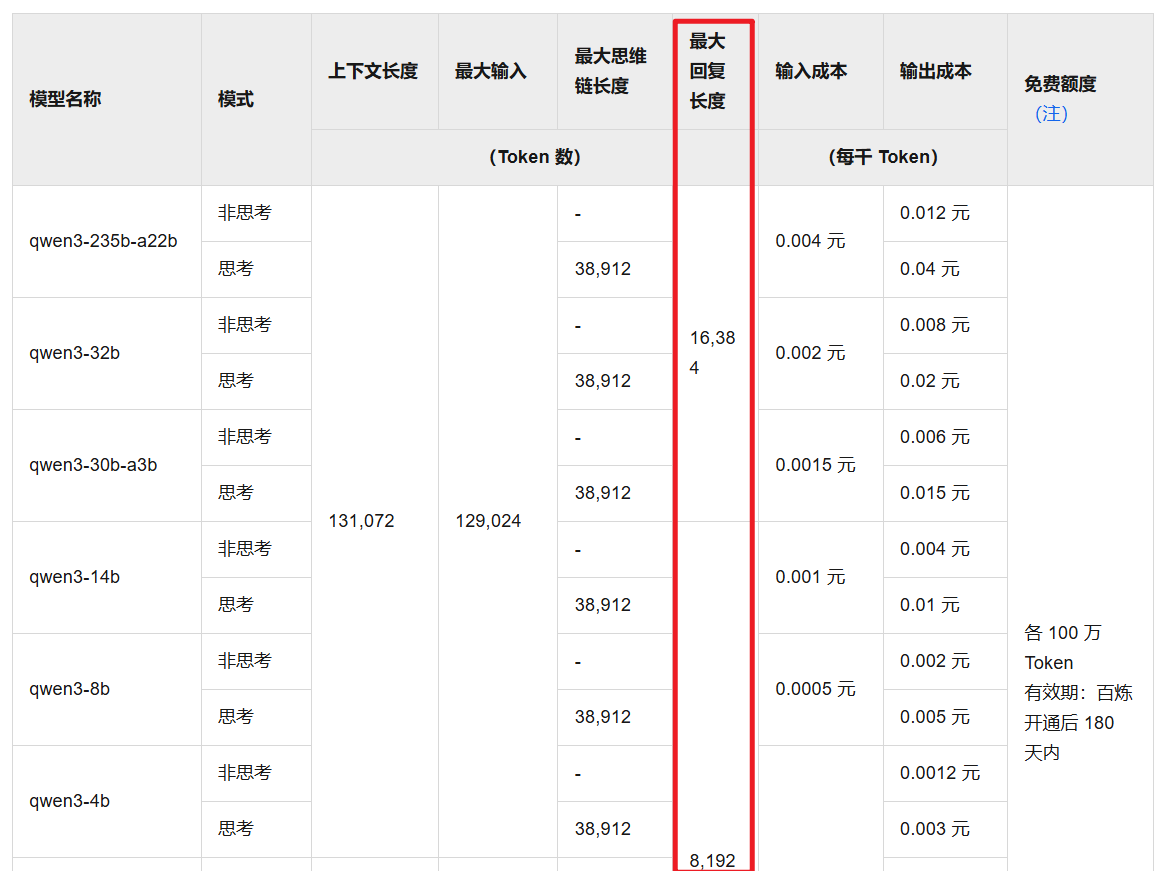
Others are similar, just pay attention to the maximum output length or maximum output token, not the context length.
Important Note: Be sure to find the maximum output tokens of the model you are using, not the context token, and fill it in correctly in the pyVideoTrans settings.