Custom Speech Recognition API
Starting from version v3.56, support for using Gladia's speech recognition service in this custom speech recognition channel. For specific usage, please refer to this tutorial.
If you are not satisfied with the existing speech recognition methods, you can also customize your own speech recognition API. Fill in the relevant information in the menu under Speech Recognition Settings > Custom Speech Recognition API.
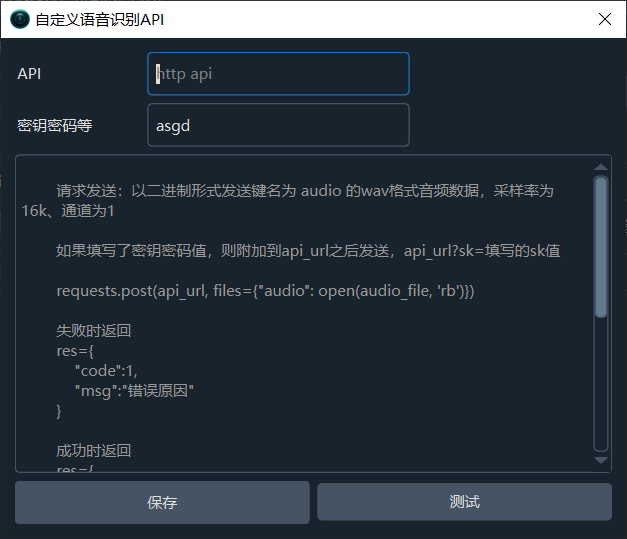
Fill in your API address starting with "http". The system will send a WAV format audio file with the key name "audio" to your provided API address. The audio has a sample rate of 16k and 1 channel. If your API requires authentication, enter the relevant password in the key field. The password will be appended to the API address as sk=password.
requests.post(api_url, files={"audio": open(audio_file, 'rb')})
Your API must return data in JSON format. In case of failure, set code to 1 and msg to the reason for the error.
Failure response:
res={
"code":1,
"msg":"Error reason"
}Success response:
res={
"code":0,
"data":[
{
"text":"Subtitle text",
"time":"00:00:01,000 --> 00:00:06,500"
},
{
"text":"Subtitle text",
"time":"00:00:06,900 --> 00:00:12,200"
},
... multiple entries
]
}As shown below, if a key password value is provided, it will be appended to the api_url when sending: api_url?sk=provided_sk_value.
requests.post(api_url, files={"audio": open(audio_file, 'rb')})
# Failure response
res={
"code":1,
"msg":"Error reason"
}
# Success response
res={
"code":0,
"data":[
{
"text":"Subtitle text",
"time":"00:00:01,000 --> 00:00:06,500"
},
{
"text":"Subtitle text",
"time":"00:00:06,900 --> 00:00:12,200"
},
]
}