In the faster-whisper speech recognition channel, only the following settings can achieve the best sentence segmentation effect!
The principle of speech recognition is to divide the entire audio into several small segments based on silent intervals. Each segment may be 1 second, 5 seconds, 10 seconds, or 20 seconds long. These small segments are then transcribed into text and combined into subtitle form.
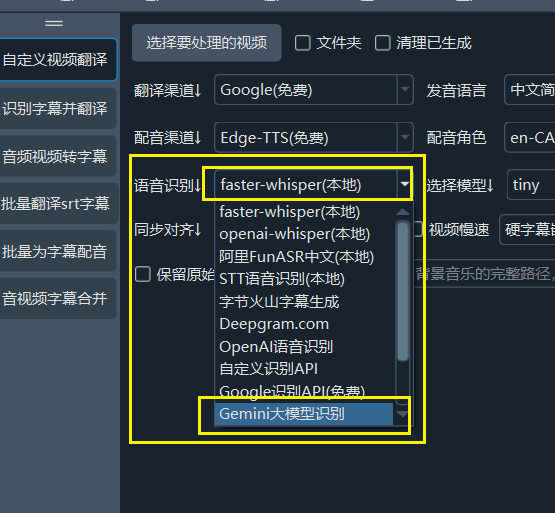
When using faster-whisper mode or GeminiAI as the speech recognition channel, the following settings can achieve relatively better recognition results.
Use a larger model: First and foremost, use a larger model. For example, the tiny model is too small and will definitely perform poorly, while the large-v2 model will perform several times better.
Optimize settings: Click
Menu → Tools → Advanced Options.
Find the faster/openai speech recognition adjustment section and make the following modifications:
- Speech threshold: Set to
0.5 - Minimum duration/milliseconds: Set to
0 - Maximum speech duration/seconds: Set to
5 - Silence separation/milliseconds: Set to
140 - Speech padding: Set to
0
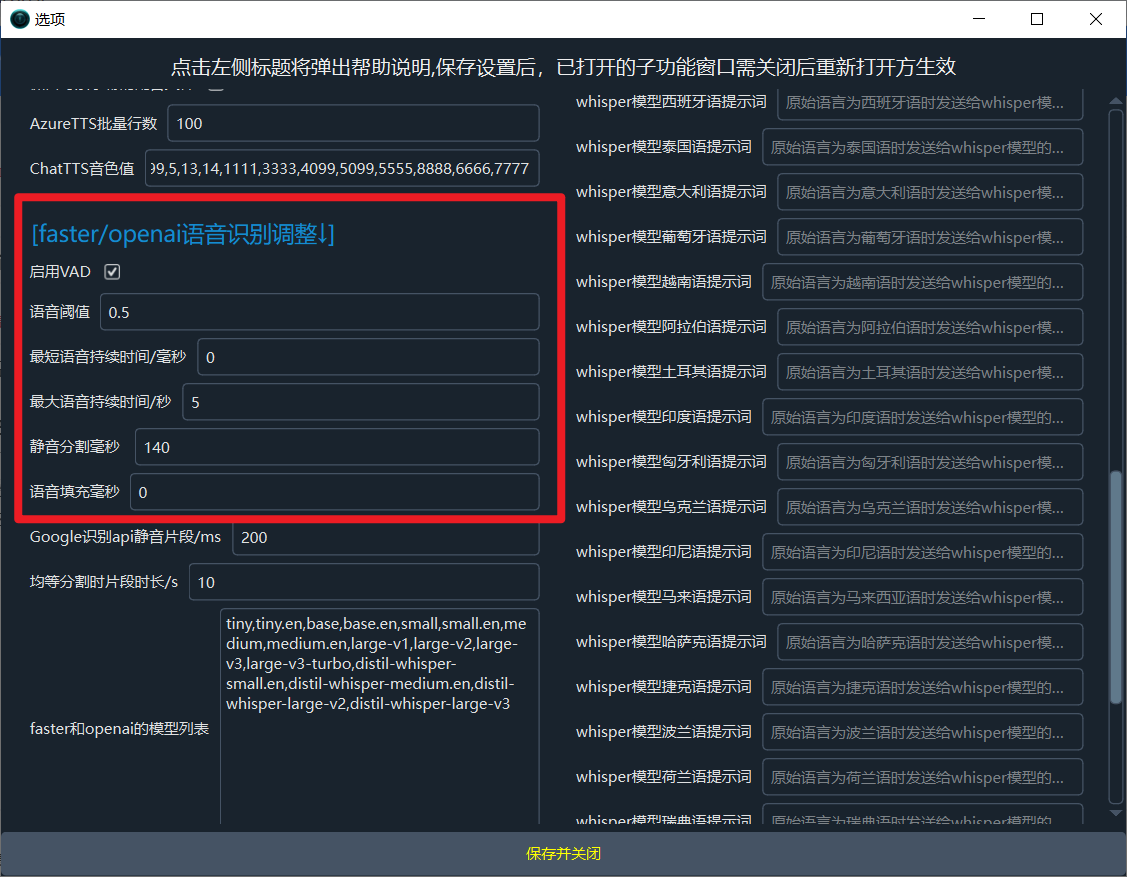
Of course, you can also test other values based on your needs.
Reduce 403 Error Rate in edge-tts (Also Applicable to Other Dubbing Channels)
Since dubbing requires connecting to Microsoft's API, which has rate-limiting measures, 403 errors cannot be completely avoided. However, you can reduce the occurrence of errors with the following adjustments:
Navigate to Menu → Tools/Options → Advanced Options → Dubbing Adjustment, as shown below.
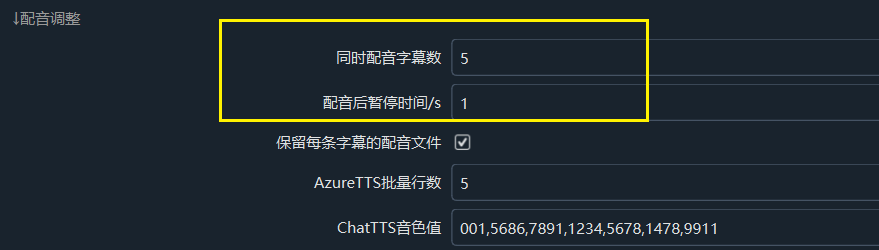
- Number of simultaneous dubbing subtitles: It is recommended to set it to 1. Reducing the number of subtitles dubbed simultaneously can lower errors caused by high request frequency. This setting also applies to other dubbing channels.
- Pause time after dubbing/seconds: For example, set it to 5, meaning pause for 5 seconds after completing the dubbing of one subtitle before proceeding to the next. It is recommended to set this value to 5 or higher to reduce the error rate by extending the request interval.