Improving the Quality of AI-Translated Subtitles
When using AI to translate SRT subtitles, there are typically two approaches.
Approach 1: Translate the Complete Subtitle Format, Including Untranslated Elements Like "Line Numbers" and "Timestamps."
As in the example below, send the complete format:
1
00:00:01,950 --> 00:00:04,950
Organic molecules have been discovered in the Five Old Stars system.
2
00:00:04,950 --> 00:00:07,902
We are approaching a third contact with multiple elements.
3
00:00:07,902 --> 00:00:11,958
The microwave is truly launching a filming mission that has been going on for a year.Advantages: Maintains context, resulting in better translation quality.
Disadvantages: Besides wasting tokens, it may lead to subtitle format errors during translation, resulting in a translation that is no longer a valid SRT subtitle format. For example, English symbols like , : might be incorrectly changed to Chinese symbols, or line numbers and timestamp rows might be merged into one line.
Approach 2: Send Only the Subtitle Text Content and Then Replace the Corresponding Text in the Original Subtitles with the Translation.
In the following format, only send the subtitle text:
Organic molecules have been discovered in the Five Old Stars system.
We are approaching a third contact with multiple elements.
The microwave is truly launching a filming mission that has been going on for a year.Advantages: Ensures that the translation result is always a valid SRT subtitle format.
Disadvantages: Very obvious: translating subtitle text line by line makes it impossible to maintain context, greatly reducing translation quality.
To solve this problem, the software supports translating multiple lines at once, defaulting to 15 lines of subtitles, which can address context to some extent.
But this leads to a new problem: different languages have different grammatical rules and sentence structure order, so the original 15 lines may become 14 lines, 13 lines, etc. after translation, especially when the previous and next lines are the same sentence in grammatical structure.

If the 15 original subtitle lines are no longer 15 lines after translation, this will definitely lead to subtitle chaos. To solve this problem, when the number of translated lines does not match the number of original subtitle lines, the software re-translates line by line to ensure that the number of lines before and after the translation is exactly the same, sacrificing consideration of context.
The software defaults to using the second approach, after all, usable is more important than good.
From version v2.52, support for the first translation method has been added. It is not enabled by default. If you want to enable it, you need to manually turn it on. After it is enabled, when using ChatGPT/Gemini/AzureGPT/302.AI/ByteDance Volcano Engine/LocalLLM AI for translation, the complete formatted SRT subtitles will be sent for translation, which can better maintain context and improve translation quality.
But you must pay attention to the problems mentioned in the first method that may occur, causing the result to not be a valid SRT subtitle, possibly resulting in parsing errors or losing everything after the error. It is recommended to only use this method on sufficiently intelligent models, such as GPT-4o-mini or larger models. If it is a locally deployed model, it is not recommended to use this method. Limited by hardware resources, locally deployed models are generally small in scale and not intelligent enough, making it easier to cause chaotic translation results.
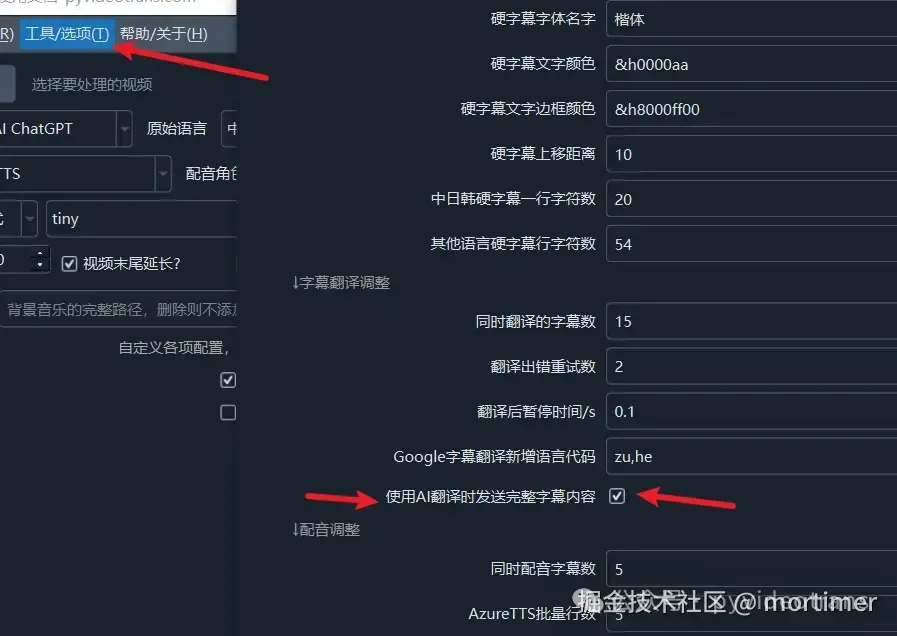
Enabling the First Translation Method:
Menu -- Tools/Options -- Advanced Options -- Subtitle Translation Area -- Send Complete Subtitles During AI Intelligent Translation
Adding a Glossary
You can add your own glossary to each prompt, like this:
**During the translation process, be sure to use** the glossary I provide to translate the terms and maintain consistency of terminology. The specific glossary is as follows:
* Transformer -> Transformer
* Token -> Token
* LLM/Large Language Model -> Large Language Model
* Generative AI -> Generative AI
* One Health -> One Health
* Radiomics -> Radiomics
* OHHLEP -> OHHLEP
* STEM -> STEM
* SHAPE -> SHAPE
* Single-cell transcriptomics -> Single-cell transcriptomics
* Spatial transcriptomics -> Spatial transcriptomics