The core principle of video translation software is: recognizing text from spoken audio in the video, translating the text into the target language, dubbing the translated text, and finally embedding the dubbing and text into the video.
The first step involves recognizing text from the spoken audio in the video, and the accuracy of this recognition directly affects the subsequent translation and dubbing.
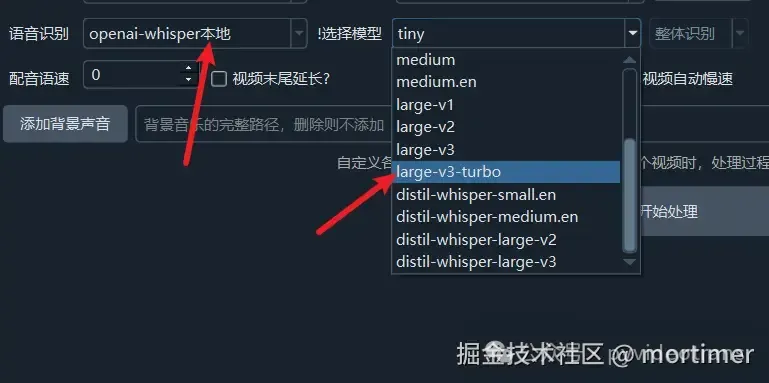
OpenAI-Whisper Local Mode
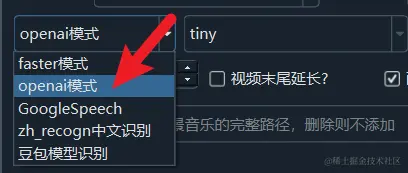
This mode uses the official open-source Whisper model from OpenAI. It is slower compared to faster modes but offers the same accuracy.
The model selection on the right is similar, ranging from tiny to large-v3, with increasing computer resource consumption and higher accuracy.
Note: Although the model names are mostly the same in faster mode and OpenAI mode, the models are not interchangeable. Please download the models for OpenAI mode from https://github.com/jianchang512/stt/releases/0.0.
Large-v3-turbo Model
OpenAI-Whisper recently released the large-v3-turbo model, which is optimized from large-v3. It offers similar recognition accuracy but with significantly reduced size and resource consumption, making it a suitable replacement for large-v3.
How to Use
Upgrade the software to version v2.67.
After speech recognition, select "OpenAI-Whisper Local" from the dropdown menu.
Select "large-v3-turbo" from the model dropdown menu.
Download the large-v3-turbo.pt file and place it in the models folder within the software directory.