自定义语音识别API
v3.56版本起,支持在该自定义语音识别渠道中使用 Gladia 的语音识别服务,具体使用方法请查看该教程
如果现存的语音识别方式不满意,也可以自定义自己的语音识别api,在菜单-语音识别设置-自定义语音识别api中填写相关信息即可
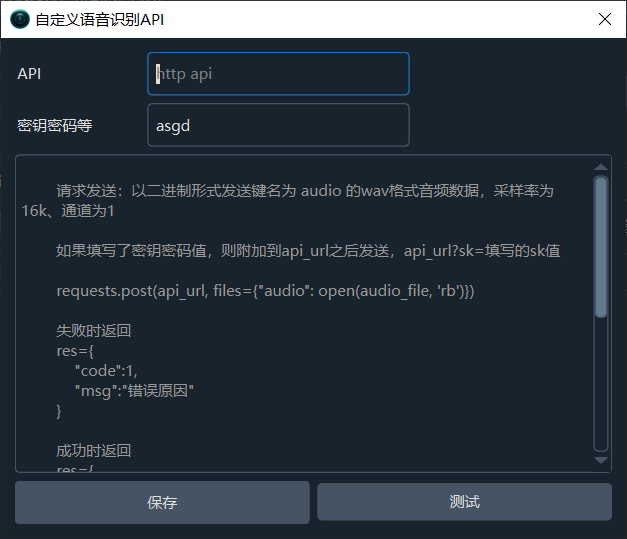
填写你的api地址,以http开头,将向你填写的api地址发送:发送键名为 audio 的wav格式音频数据,采样率为16k、通道为1,如果你的api有密钥验证,在密钥框里填写相关密码,该密码将附在api地址后以 sk=密码发送。
requests.post(api_url, files={"audio": open(audio_file, 'rb')})
你的api需要返回json格式数据,失败 时将code设为1,msg设为识别原因。
失败时返回
res={
"code":1,
"msg":"错误原因"
}成功时返回
res={
"code":0,
"data":"SRT格式的字幕字符串"
}如下,如果填写了密钥密码值,则附加到api_url之后发送,api_url?sk=填写的sk值
requests.post(api_url, files={"audio": open(audio_file, 'rb')})
#失败时返回
res={
"code":1,
"msg":"错误原因"
}
#成功时返回
res={
"code":0,
"data":"SRT格式的字幕字符串"
}