Tame Noise and Boost Transcription Accuracy with a Single FFmpeg Command

When I do speech-to-text transcription, my biggest headache is noise. Recordings often contain wind, electrical hum, keyboard clicks, echo... When these noises pile up, transcription models tend to miss words or even fail to recognize entire sentences.
There are many noise reduction methods online, most of which are AI-based "large model" solutions like RNNoise, DeepFilterNet2, resemble-enhance, etc.
The results are indeed good, but they come with significant problems:
- Models can be hundreds of MB or even several GB in size.
- Downloads are slow and prone to interruption, especially with network issues in certain regions.
- Processing is slow, making them unsuitable for batch operations.
- Most importantly, they are not ideal for packaging and distribution.
For me, the goal is simple: I just want to clean up the audio a bit before transcription to reduce the number of missed sentences. The noise reduction doesn't have to be perfect, as long as it's simple enough and lightweight enough.
Initial Attempt: afftdn
At first, I used FFmpeg's built-in frequency-domain noise reduction filter:
ffmpeg -i 1.wav -af afftdn 1_denoised.wavThe command was short enough, but—it had almost no effect. Slight background noise, wind, and breathing sounds were virtually unchanged.
I tried adjusting the parameters:
-afftdn=nf=-30The intensity did increase, but it also cut into the vocals, making the sound muffled and watery. I figured I might need to combine several filters.
Improved Solution: A Four-Filter Combination
In the end, I settled on this one-line command:
ffmpeg -i 1.wav -af "highpass=f=80,afftdn=nf=-25,loudnorm,volume=2.0" 1_clean.wavThe noise reduction effect improved immediately, and the recognition accuracy became noticeably more stable.
The following tests were all conducted using Whisper's "tiny" model.
- This is the transcription result without noise reduction. It's clear that several sentences at the beginning were missed.
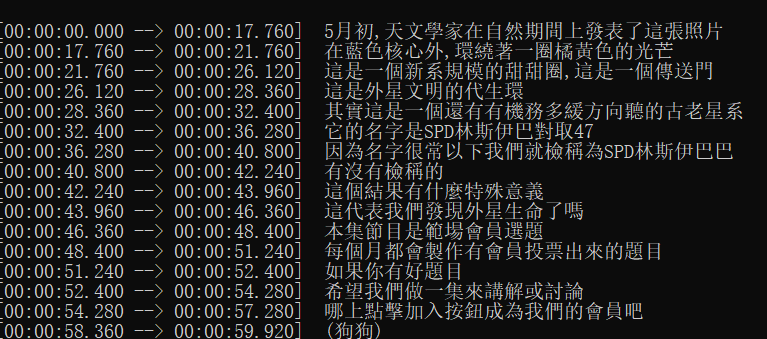
- This is the transcription result after applying the noise reduction parameters.
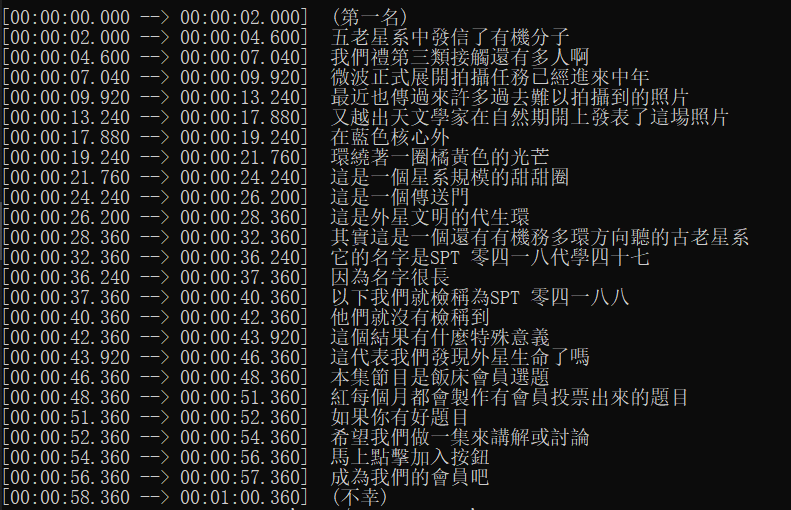
The improvement is quite significant. Not only are there no more missed sentences, but the sentence segmentation is also more logical.
Let's break down its components 👇
1️⃣ highpass=f=80
A high-pass filter that removes low-frequency noise below 80Hz. This is typically ambient hum or microphone floor noise, and it has almost no effect on human speech. Adding this filter makes the overall audio sound "cleaner" right away.
2️⃣ afftdn=nf=-25
The core noise reduction filter. nf stands for noise floor, with a default of -20. I set it to -25, which is slightly stronger but doesn't muffle the sound too much. This parameter acts as an "intensity control"—the lower the value, the stronger the noise reduction.
3️⃣ loudnorm
Loudness normalization. After noise reduction, the audio volume can sometimes fluctuate. loudnorm makes the overall sound more natural and balanced.
4️⃣ volume=2.0
Finally, I amplify the volume by a factor of two to compensate for the energy loss from noise reduction. If the volume is too high or results in clipping, you can adjust it to 1.5. In some scenarios, 1.5 works better than 2.0.
🤔 Why Not Use AI Noise Reduction?
Some might ask: Doesn't FFmpeg have the neural network-based arnndn filter? It works better.
Yes, it is more powerful, but the problem is—it's a hassle. Many FFmpeg builds don't even include this filter. To use it, you have to:
- Download the
.rnnnmodel yourself. - Configure the path.
- Ensure compatibility across different systems.
- Include the model file when sharing the script.
For someone like me who wants a single command that just works and needs to share it with other non-technical users, this isn't practical.
In contrast, the highpass + afftdn combination is a purely built-in solution. It doesn't depend on external models, it's fast, and it's highly compatible.
⚡ Real-World Experience
I use this command as a pre-processing step before speech-to-text transcription, and the results have been very consistent. Ambient noise is significantly reduced, and the transcription model's error rate has dropped considerably.
More importantly:
- It runs in just a few seconds.
- It requires no extra files.
- It works on any system.
- It's easy to use for batch processing.
For anyone who needs a simple deployment, fast execution, and predictable results, this command is "just right."
✅
When it comes to noise reduction, there's no perfect solution. AI models can achieve incredible results but have a high barrier to entry. Traditional filters are less effective but are stable and universal.
My goal isn't audio restoration; it's to make speech transcription more reliable. And this one-line command strikes the perfect balance between "effectiveness" and "simplicity":
ffmpeg -i 1.wav -af "highpass=f=80,afftdn=nf=-25,loudnorm,volume=1.5" 1_clean.wav